In the field of Privacy Enhancing Technologies (or PrivTech), one truth is becoming increasingly apparent: there is no silver bullet in privacy approaches. Each data use case has to be considered separately. Typical requirements we discuss with customers are
- What analytical quality is needed?
- Is time to market for each use case a factor?
- What privacy protection is needed or wanted?
- Which machine learning use cases do you want to realize?
- Do you plan to use this for test data generation?
The above will heavily influence which technology works for you.
That’s a lot of things to consider at once. Thankfully, we’ve done the work already. Here, we summarize how privacy approaches like synthetic data, pseudonymized data, Differential Privacy and Aircloak perform in the above-mentioned dimensions.
Baseline: Raw Data
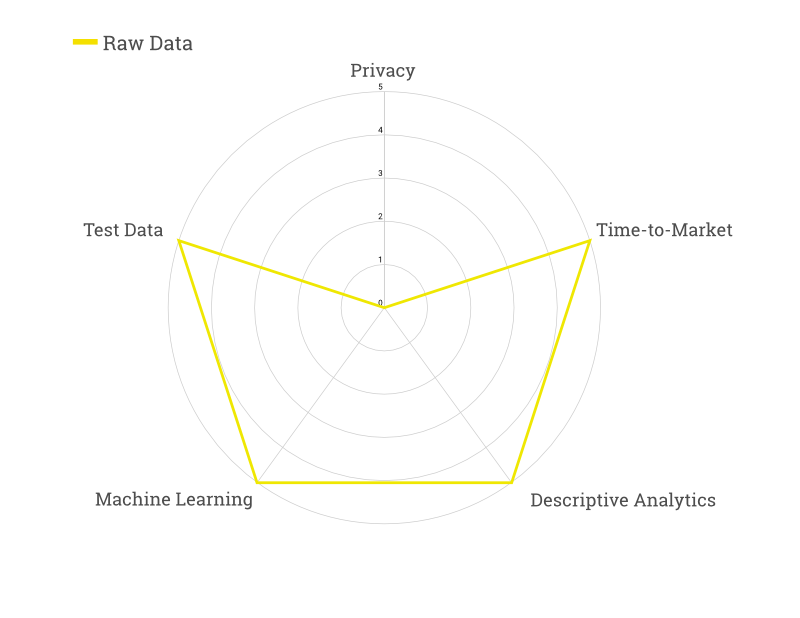
If you’re reading this article, you probably won’t want to work with raw data, but we’re including this here as a baseline.
Unsurprisingly, raw data performs perfectly in all metrics except privacy. Raw data must be subject to strict security guidelines and various technical and organizational measures must ensure that it is and remains protected.
Pseudonymized Data
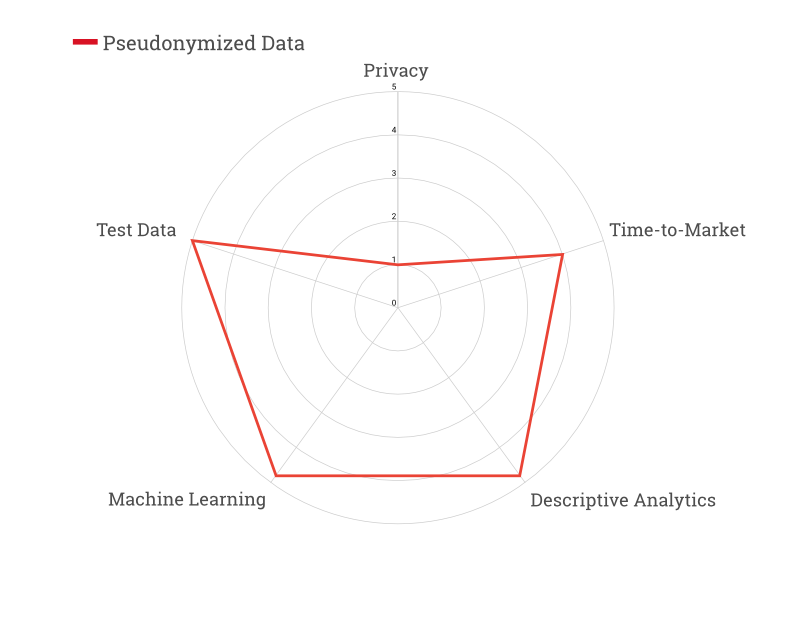
In terms of analytical power, pseudonymization is the next best thing after raw data, allowing for technologically advanced use cases like machine learning. Almost all analytics tasks can be achieved with pseudonymized data since the data utility is mostly preserved, and the use as test data is straightforward.
While pseudonymized data is certainly more private than raw data, individuals can still be identified in the data with the right external knowledge. As a result, the GDPR considers pseudonymized data to still be personal data (see details on the distinction here).
It’s also important to note that especially in the US, the terms data masking, pseudonymization and anonymization are often used synonymously, although there are significant differences.
Synthetic Data

The creation of privacy-preserving synthetic data sets is a very difficult and highly individualized process. However, synthesized data can often be used with existing machine learning tools in a straightforward fashion, as well as a basis for test data.
Again, this can come at the cost of privacy. Some technological approaches are currently attempting to combine synthetic data with data protection guarantees such as differential privacy. While the idea is laudable, there are strong limitations to time-to-market, scalability and usability. For descriptive analytics, the utility of synthetic data is often limited.
Differential Privacy
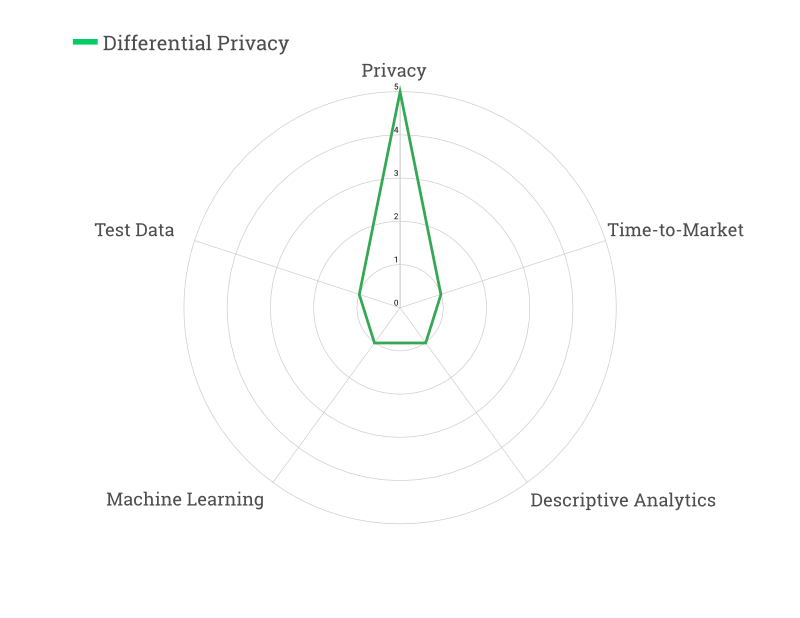
In recent years there has been a lot of interest in the Differential Privacy model for data privacy. In contrast to all other methods, it can be used to mathematically prove how private a dataset really is. This gives an enormous legal advantage, but unfortunately the usability of a data set becomes very limited. The so called “Privacy Budget” restricts the number of queries that are allowed on a data set.
Because of the granularity needed in test data sets, using Differential Privacy (directly) to generate them makes little sense. Time-to-market is also a weak point: Facebook for example, using multiple engineers and experts, spent over 1 year releasing one single differential private dataset.
Aircloak
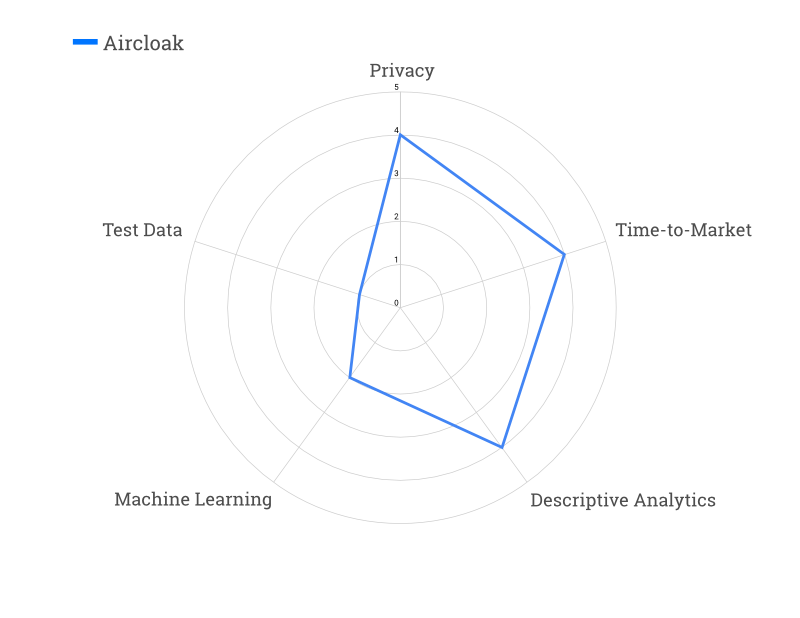
Instead of anonymizing the source data prior to analysis, Aircloak Insights performs analytics on the unprocessed (raw or pseudonymized) data. The analytics output is then instantly and automatically anonymized as queries are run. While training machine learning models with this approach requires a bit of experience, Aircloak allows for precise and flexible explorative analytics. For test data generation, the same limitations as for Differential Privacy apply.
Aircloak has been confirmed to be fully compliant with European Guidelines for anonymization by the French Data Protection Authority CNIL. As the world’s first and only off-the-shelf privacy-preserving analytics solution, the fast time to market is a great strength.
The Big Picture
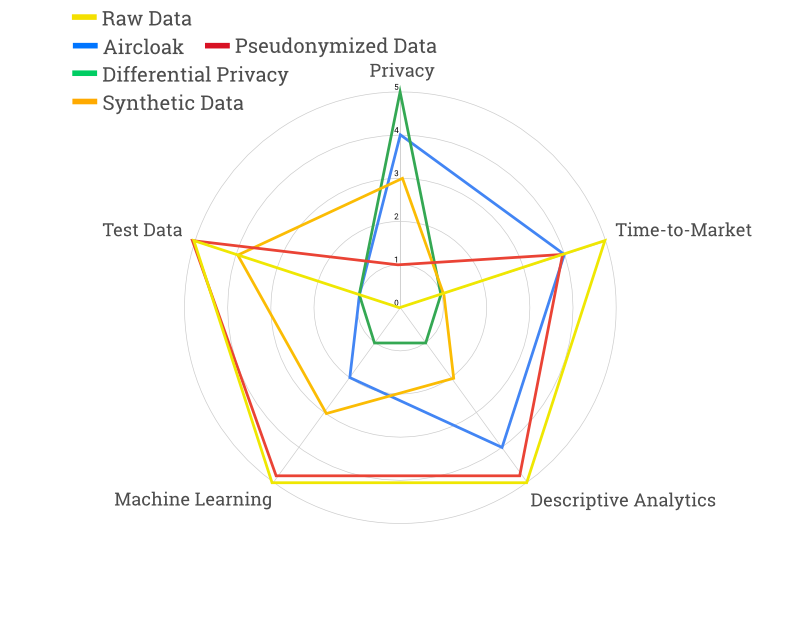
Since each privacy approach comes with its advantages and disadvantages, weighting them carefully against your use case is advised. As a general rule, a high level of data protection is usually achieved at the expense of lower data usability and vice versa.
The ratings are guidelines based on our experience and certainly not carved in stone. If you disagree with our summary, feel free to reach out to us on social media (like twitter or LinkedIn) or at solutions@aircloak.com. We’re very happy to get further input on the topic!
Otherwise, we hope this is useful. We strongly believe that using the right approaches, many data driven business models can be set up the right way: legally safe for organizations and truly privacy preserving for consumers.
Categorised in: Aircloak Insights, Anonymization, GDPR, Privacy, Synthetic Data
Aircloak Aircloak Insights Analytics Differential Privacy Machine Learning Privacy Synthetic Data Test Data