Bei unserer täglichen Arbeit mit Kunden, aber auch in persönlichen Gesprächen gibt es beim Thema Anonymisierung immer viel klarzustellen. Das fängt bei harmlosen Fragen an (erschreckend häufig: “Was ist nochmal der Unterschied zwischen Anonymisierung und Verschlüsselung?”), reicht aber bis hin zu schwerwiegenden Missverständnissen – die im Ernstfall ebenso schwerwiegende Konsequenzen haben können.
Räumen wir damit auf! Bringen wir Licht ins Dunkel! Aircloak präsentiert…:
Die sieben Mythen der Datenanonymisierung.
Mythos #1: Anonymisierung ist durch die DSGVO wichtig geworden
An vielen Stellen hätte man sich die DSGVO vielleicht noch konkreter gewünscht – aber in der Unterscheidung zwischen Anonymisierung und Pseudonymisierung wurde klar Stellung bezogen: Nur anonymisierte Daten sind wirklich nicht mehr persönlich und können deswegen weitreichend und ohne datenschutzrechtliche Einschränkungen eingesetzt werden.
Dadurch ist das Thema nun zwar in aller Munde – aber natürlich galt Ähnliches schon in der Vergangenheit. Bereits das deutsche Bundesdatenschutzgesetz (BDSG) machte klar, dass pseudonymisierte Daten personenbezogen sind und somit unter seinen Anwendungsbereich fallen. In den USA hatte man bereits im 19. Jahrhundert die Wichtigkeit von Anonymisierung für Volkszählungen erkannt und eine Reihe von (später computergestützten) Methoden entwickelt, mit denen die Privatsphäre der Bürger geschützt wird.
Der Grund, dass dem Thema “auf einmal” so viel Bedeutung zugemessen wird, ist doch ein ganz anderer: Noch nie haben wir Daten in diesem Maße erzeugt und aufgenommen, ein Großteil davon fällt in die Kategorie ’Persönliche Daten’. Schuld an dem plötzlichen Umdenken ist nicht die DSGVO – Schuld ist die Digitalisierung.
Mythos #2: Keine identifizierenden Merkmale = keine persönlichen Daten
Wir stellen uns immer auf ein langes Gespräch ein, sobald wir hören “Wir anonymisieren unsere Daten selber – wir löschen die Namen gleich raus, die brauchen wir gar nicht für unsere Analysen.” Dass oft überhaupt keine identifizierenden Merkmale (sog. “PIIs” = Personally Identifiable Information) notwendig sind, ist den meisten nicht bekannt – bis es schief geht. Bereits vor vielen Jahren wurde zum Beispiel gezeigt, dass 63% der US-Amerikanischen Bürger allein durch Postleitzahl, Geburtsdatum und Geschlecht eindeutig identifizierbar sind.
Auch Profis, die es vermeintlich besser wissen sollten, machen diesen Fehler. Beispielsweise bietet IBM Watson seit Neuestem “Anonymisierung” an, die einzelne Spalten auf drei verschiedene Arten verschleiert: Löschung, Ersetzung (Pseudonyme) und Maskierung (ähnlich aussehende Daten). Keine dieser Methoden würde unter europäischem (!) Recht als korrekt anonymisierend gelten. Die geltenden Kriterien der Anonymisierung in Europa finden Sie im Paper der Article 29 Working Party.
Mythos #3: Anonymisierung zerstört Daten und behindert Innovation
Ja, Anonymisierung bedeutet per Definitionem das Entfernen bestimmter (nämlich persönlicher) Merkmale aus Daten. Somit können Details verloren gehen, die für bestimmte Auswertungen wichtig wären. Es sei einmal dahingestellt, ob jene Auswertungen auch als wünschenswert zu bezeichnen sind.
Allerdings gibt es viele Ansätze zur Anonymisierung. Moderne Methoden schaffen es dabei, den Spagat zwischen Datenqualität und Datenschutz sicherer hinzukriegen. Je nach Anwendungsfall mag die eine oder andere Lösung bessere Ergebnisse liefern und somit innovative Weiterverwendung ermöglichen. Mein Mitgründer Paul Francis zeigte letztes Jahr in einem Blog-Artikel, wie stark sich zum Beispiel zwei anonymisierte Heatmaps unterscheiden können:
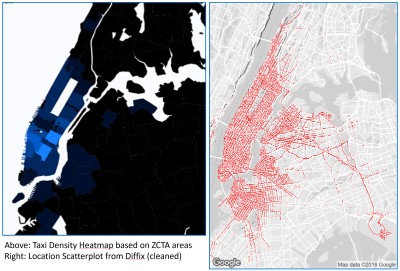
Letztlich sei noch ein weiterer Punkt erwähnt: in unserem derzeitigen technischen Umfeld ist Anonymisierung oft die Innovation. Wir erwarten, dass unsere Daten richtig behandelt werden – 87% der Endkunden geben inzwischen an, Dienstleister zu wechseln, wenn dieser mit ihren persönlichen Daten nicht adäquat umgeht.
Mythos #4: “Differential Privacy” macht Daten sicher
Spätestens seit Apples großer Bekanntgabe, Differential Privacy zu nutzen, ist dieser Ansatz vielen ein Begriff. Leider ist meistens nicht klar, dass es sich bei Differential Privacy gar nicht um einen Algorithmus handelt, geschweige denn um ein Produkt, sondern um die Eigenschaft eines Algorithmus. Das Level an Datenschutz, das gewährleistet wird, ist dann von der genutzten Implementierung und vielen Variablen abhängig, und kann, das ist der Clue, gemessen werden. Zu sagen eine Datenbank sei “differentially private” bedeutet also nicht, dass sie anonym ist – sondern dass man messen kann, wie anonym sie ist.
Mythos #5: Synthetische Daten sind anonym
Auch in synthetischen, also künstlich erzeugten Daten können persönliche Informationen enthalten sein. Ein guter synthetischer Datensatz basiert nämlich auf realen Zusammenhängen – wie viele und wie genau muss (wie bei vielen anderen Ansätzen) abgewogen werden.
Ein Beispiel: Karl Müller ist Geschäftsführer eines 50-Mann Betriebs und zahlt sich selbst ein wesentlich höheres Gehalt aus, als es schicklich wäre. Ein synthetischer Datensatz, der aufgrund dieses Betriebs erstellt wurde, mag diesen Zusammenhang enthalten: dabei heißt dann der Geschäftsführer Hans Meier, aber um die Einkommensstruktur richtig abzubilden, verdient er trotzdem das fünffache seiner Mitarbeiter. Ein Rückschluss auf Herrn Müller ist somit einfach möglich.
Moderne Algorithmen zur Erstellung synthetischer Daten trainieren Machine Learning-Modelle auf den originalen Daten und kreieren dann, teils bedarfsweise, neue Datensätze daraus. Das bedeutet: persönliche Daten die in so ein Modell übergegangen sind, lassen sich potentiell (!) auch in den synthetischen Daten finden. Dass ML-Ansätze dazu anfällig sind, persönliche Daten zu kopieren, zeigte zum Beispiel Vitaly Shmatikov bereits in 2017.
Mythos #6: KI verträgt sich nicht mit anonymen Daten und braucht sie auch nicht
Vielleicht zuerst zum zweiten Punkt: Natürlich ist auch die Verarbeitung persönlicher Daten durch eine künstliche “Intelligenz” trotzdem eine Verarbeitung im Sinne der DSGVO und deswegen durch selbige reguliert. Artikel 22 weist sogar ausdrücklich darauf hin, dass die rein maschinelle Verarbeitung persönlicher Daten oft nicht erlaubt ist (nämlich, wenn sie zu einer “erheblichen Beeinträchtigung” führen kann).
Spannender und kontroverser ist der erste Punkt: Kann modernes maschinelles Lernen anhand von anonymen Daten erfolgen? Die Antwort: Ja und nein. Viele standardmäßig genutzten Algorithmen basieren auf der Annahme, Zugriff auf Rohdaten zu haben. Aber wie mir ein Redakteur eines wichtigen Journals in dem Bereich kürzlich sagte: “Nur weil die Algorithmen nicht so entworfen sind, heißt das noch lange nicht, dass sie nicht so entworfen werden können.” Das Feld des “privacy preserving machine learning” entwickelt sich rapide. Auch bei Aircloak haben wir einzelne Modelle äußerst erfolgreich und völlig anonym trainieren können.
Mythos #7: Anonyme Daten gibt es gar nicht
Erst kürzlich bin ich über diesen netten Tweet gestolpert:
Hot debate at #AI Policy Congress: is perfectly de-identifiable data possible?
• Industry/gov speakers: “maybe”
• @MIT faculty in audience: “no” pic.twitter.com/bLr8pv9KxD— Ross Dakin (@rossdakin) 15. Januar 2019
Ein Forscher am MIT behauptet da also, “perfekt de-identifizierte Daten” seien nicht möglich. Stimmt das?
Im großen Stil perfekt anonymisierte Datensätze sind tatsächlich schwer vorzustellen. Erst kürzlich durfte ich ein Panel moderieren, bei dem sich viel der Diskussion auch um das Thema Messbarkeit von Anonymisierung drehte. So viel unterschiedliche Meinungen es gab, im Kern waren sich fast alle Teilnehmer an einem Punkt einig: wie bei IT-Security kann keine hundertprozentige Sicherheit garantiert werden und oft gibt es eine Risikoabschätzung.
Somit fällt das Ganze zurück auf die Definition der Anonymität. Je nach Rechtsraum wird hier mit unterschiedlichem Maß gemessen – üblicherweise eines, das erfüllt werden kann. In Europa gilt hier derzeit noch die Opinion 05/14 der Article 29 Working Party, die sagt: Daten sind dann anonymisiert, wenn drei Dinge unmöglich sind
- das Herausfiltern eines Einzelnen (“singling out”),
- die Verknüpfung von Datenpunkten eines Einzelnen um ein größeres Profil zu bilden (“linkability”)
- und die Möglichkeit aufgrund eines Attributs auf ein anderes Attribut zu schließen (“inference”).
Es ist tatsächlich schwer, diese Richtlinien zu erfüllen – aber bei weitem nicht unmöglich. Aircloak Insights erledigt das zum Beispiel ganz automatisch, bevor man sagen kann “Die Achtung des Privatlebens ist ein Grundrecht nach der Europäischen Menschenrechtskonvention”.
Categorised in: Aircloak Insights, Anonymisation, GDPR, Privacy
Data Anonymisation Myths Privacy Enhancing Technologies