Wenn man sich mit Datenanonymisierung auseinandersetzt, stößt man früher oder später auf Differential Privacy. Viele Privacy-Forscher betrachten es sogar als den Königsweg in der Anonymisierung. Außerdem setzen seit geraumer Zeit namhafte Technologieunternehmen wie Apple oder Google darauf und unterstreichen damit ihren Fokus auf Datenschutz. Aber was genau steckt hinter diesem Ansatz und warum hat er bei Datenschutzexperten einen so guten Ruf? Soll nun jedes Unternehmen, das sensible Daten analysiert, Differential Privacy nutzen?
Um das Konzept von Differential Privacy besser zu verstehen, erklären wir hier die Technologie in drei verschiedenen Schwierigkeitsgraden, mit all ihren Vor- und Nachteilen und in aufsteigender Komplexität.
Schwierigkeitsgrad: Einfach
Differential Privacy für Fünfjährige
Im englischen Sprachraum hat sich bei der Vereinfachung von komplexen Themen das Format “Explain it like I’m 5”, abgekürzt ELI5 bewährt – daher starten wir mit einer sehr einfachen Erklärung, gerichtet an Fünfjährige:
Deine Eltern wissen eine Menge über dich, wie zum Beispiel, welches Gemüse dir nicht schmeckt. Du möchtest aber bestimmt nicht, dass jeder das weiß. Um solche Arten von Geheimnissen bewahren zu können, braucht man Privatsphäre. Aber der Mann, der dir ein Mittagessen im Kindergarten macht, möchte vielleicht wissen, dass es in der Gruppe Kinder gibt, die keine Tomaten mögen. Dafür muss er allerdings nicht wissen, dass du eines dieser Kinder bist. Meistens reicht es aus, wenn er weiß, dass es vielleicht 4 oder 5 Kinder gibt, die keine Tomaten mögen. Diese Art der Privatsphäre wird als Differential Privacy bezeichnet.
Datenanonymisierung heute
In nahezu jeder Branche werden digitale und datengetriebene Geschäftsmodelle entwickelt, um Kunden neue Produkte und Dienstleistungen anzubieten. Wenn alles reibungslos läuft, ist es eine klassische Win-Win-Situation – der Kunde erhält beispielsweise per Newsletter ein unschlagbares und maßgeschneidertes Angebot für eine Reise nach Japan, wohin er schon seit Ewigkeiten reisen möchte. Das Unternehmen steigert den Umsatz und spart Kosten, da das Marketingbudget viel effizienter ausgegeben werden kann als bisher. Das bedeutet aber auch, dass Unternehmen mit Kundeninformationen äußerst sorgfältig umgehen müssen. Denn oft wissen sie nicht nur von Vorlieben für Reiseziele, sondern auch von viel privateren Dingen, wie z.B. Banken über Transaktionsdaten oder Krankenhäusern über Krankheiten von Patienten.
Angenommen, ein Unternehmen möchte seine Daten analysieren, um beispielsweise festzustellen, wie gut seine Targeting-Strategien bei Kunden funktionieren. Ein auf Differential Privacy basierender Anonymisierungsmechanismus kann beim Schutz dieser sensiblen Daten helfen.
Dabei ist Differential Privacy erstmal “nur” eine mathematische Definition von Privatsphäre.
Mit dieser Definition (in Form des Parameters Epsilon, dazu später mehr) ist es möglich, genau zu quantifizieren, wie sicher oder anonym Daten in einem Datensatz sind. Wenn ein Analyst mit einem solchen Datensatz arbeitet, ist es ihm nicht mehr möglich, einzelne Personen zu identifizieren und er erhält nur ungefähre, und keine exakten Ergebnisse.
Einen solchen mathematischen Beweis von Privatsphäre zu haben, war etwas völlig Neues in der IT. Stellen Sie sich vor, Sie erfinden ein Auto, das zu 100% verkehrssicher ist und keine Unfälle verursachen kann. Da ist es verständlich, dass viele Menschen von einem solchen Konzept zunächst begeistert sind.
Schwierigkeitsgrad: Mittel
Privacy Budget – Bei der Analyse muss gespart werden
Natürlich anonymisiert Mathematik allein einen Datensatz noch nicht. Es muss dafür einen Anonymisierungsmechanismus geben, mit dem sich die Anonymität auch mathematisch beweisen lässt. Typischerweise funktioniert Differential Privacy, indem Daten etwas Rauschen hinzugefügt wird. Stellen Sie sich das in etwa so vor, als würden Sie ein Gesicht verpixeln, um die Identität einer Person zu verbergen. Die Menge des hinzugefügten Rauschens ist dabei von großer Relevanz – mehr Rauschen macht Daten zwar anonymer, aber auch weniger nützlich für Analysten. Im Hinblick auf Differential Privacy wird dieser Kompromiss (eng. trade-off) formal über einen Parameter namens Epsilon (ε) gesteuert.

Für verschiedene Analyse-Aufgaben werden spezielle Differential Privacy-Mechanismen eingesetzt. Es gibt inzwischen Hunderte verschiedene z.B. zum Erstellen eines Histogramms, zur Berechnung eines Durchschnitts, zur Freigabe von Mikrodaten oder zur Generierung eines Machine-Learning-Models.
Aber kommen wir zuerst auf den Kompromiss und den Parameter Epsilon zurück. Hier gibt es nämlich ein Problem: Wenn Sie ein zufälliges Rauschen verwenden, um Daten zu anonymisieren, wird jedes Mal, wenn die gleichen Daten abgefragt werden, der Grad der Anonymisierung reduziert. Dies liegt daran, dass man das Rauschen durch Mittelung herausfiltern kann, vorausgesetzt man kann genügend Abfragen durchführen. Der Wert Epsilon wird nun verwendet um festzustellen, wie streng der Schutz der Privatsphäre ist. Je kleiner der Wert, desto besser der Schutz, aber desto unpräziser sind die Ergebnisse bei der Analyse der Daten. Das bedeutet auch, je kleiner der Wert von Epsilon, desto weniger oft können Sie auf die Daten zugreifen. Genauer betrachtet verhält sich Epsilon proportional zu Ihrem Privacy Budget, da Sie sonst in der Lage wären, das Rauschen zu rekonstruieren und letztendlich die Daten zu deanonymisieren. Allerdings können Sie genau definieren, wie viel Sie von Ihrem Privacy Budget verwenden können, bis die Daten nicht mehr als anonym gelten.
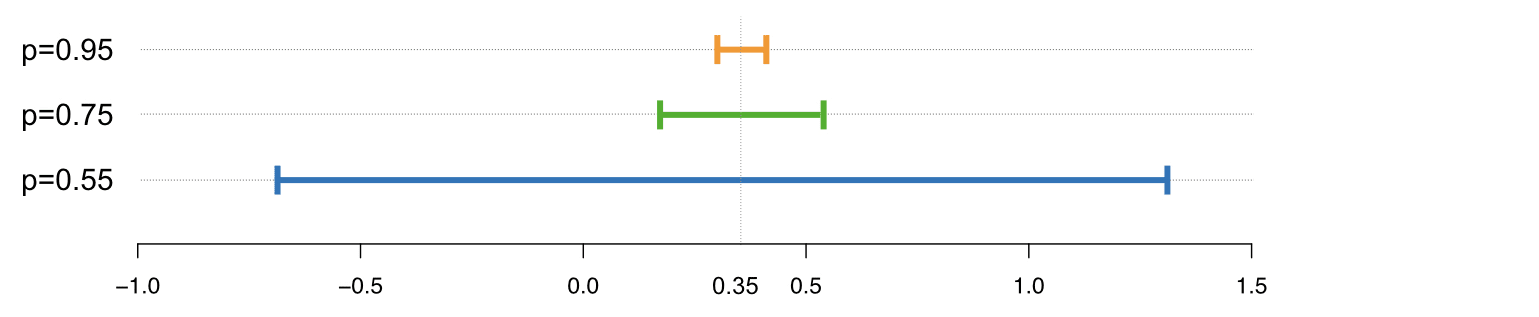
Bildnachweis: Mark Hansen, https://accuracyandprivacy.substack.com/
Im Bild oben sieht man, wie ein niedriger Parameter mehr Anonymität bietet, da die Ergebnisse zwischen -0,65 und 1,4 liegen. Je höher der Wert von Epsilon, desto präziser werden die Ergebnisse, aber die Anonymität leidet darunter.
Schwierigkeitsgrad: Gehoben
“Unsicherheit” und Differential Privacy in der Praxis
Werfen wir nun einen einen genaueren Blick auf das Konzept. Hier spielt Unsicherheit (eng. uncertainty) eine große Rolle. Wir haben bereits gelernt, dass die Anonymität, den ein Differential Privacy System bietet, aus randomisierten Rauschen kommt. Je mehr Rauschen, desto größer der Schutz der Privatsphäre.
Das Modell selbst drückt das abstrakte Konzept aus, dass bei zwei Datenbanken, die sich nur durch einen Benutzer unterscheiden, die beiden sich statistisch nicht voneinander unterscheiden lassen. Die Ununterscheidbarkeit gilt auch dann, wenn ein Angreifer allesüber die Daten weiß, außer ob diese eine Person enthalten ist oder nicht. Die Idee ist, dass, wenn ein Angreifer nicht einmal erkennen kann, ob sich eine bestimmte Person in den Daten befindet, er auch sonst nichts über denjenigen in Auskunft bringen kann und seine Privatsphäre geschützt ist.
Der sehr gut nachvollziehbare Blog-Artikel “Differential Privacy, an easy case” des Professors für Journalismus und IT-Experten Mark Hansen erklärt dies in verständlicher Form.
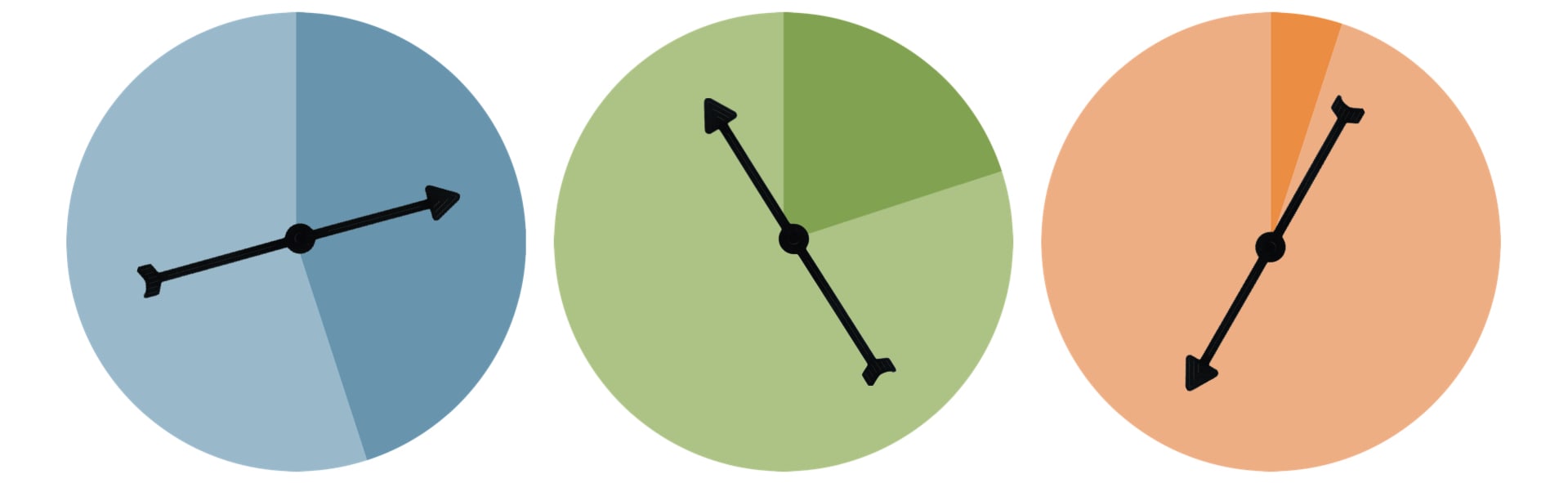
In seinem Artikel vergleicht und vereinfacht Hansen den Parameter mit Zeiger auf Scheiben, die gedreht werden. Das Ergebnis ist entweder eine “wahre” Antwort (heller Bereich) oder “falsche” Antwort (dunkler Bereich). Je höher das Epsilon, desto kleiner ist der Anteil im dunklen Bereich und desto wahrscheinlicher ist es, dass ein Umfrageteilnehmer eine “wahre” Antwort abgegeben hat.
Es ist ein weiter Weg…
Genug der Theorie – werfen wir einen genaueren Blick auf Differential Privacy in der Praxis. Die Erfinder des Konzepts schlagen vor, Epsilon zwischen 0.1 und 1 zu halten. Leider erlauben Implementierungen, die einen solchen niedrigen Wert von Epsilon berücksichtigen, nur eine geringe Anzahl (vielleicht ein Dutzend) an Anfragen zu. Einige Mechanismen, wie z.B. von Google und Apple, vereinfachen das Problem, indem sie Annahmen über die fehlende Korrelation zwischen Attributen und für dasselbe Attribut über Zeit treffen. Dadurch kann eine unbegrenzte Anzahl an Anfragen gestellt werden, aber das Rauschen ist groß (Abweichungen von hunderten oder tausenden bei Nutzerzahlen) und die Möglichkeit, beispielsweise Korrelation zwischen Attributen zu beobachten, geht verloren. Während diese Ergebnisse für die spezifischen Anwendungszwecke bei Google und Apple (z.B. Nutzerstatistiken von iPhones oder in Google Chrome) akzeptabel sind, erfordern die meisten analytischen Aufgaben weniger Rauschen und eine höhere Genauigkeit.
Infolgedessen haben viele Implementierungen von Differential Privacy ein Epsilon von weit über 10. Damit ist die Privatsphäre der Nutzer nicht mehr gesichert. Auf der anderen Seite entfernt ein Mechanismus mit einem kleinen Epsilon fast den gesamten Informationsgehalt eines Datensatzes. Darüber hinaus erfordert der mathematische Beweis, dass ein Mechanismus tatsächlich “differentially private” ist, umfangreiche Fachkenntnisse. Daher ist es kein Zufall, dass nur Unternehmen mit sehr hohen Forschungsbudget ihr Epsilon veröffentlichen. (vgl. Differential Privacy Leaders You Must Know).
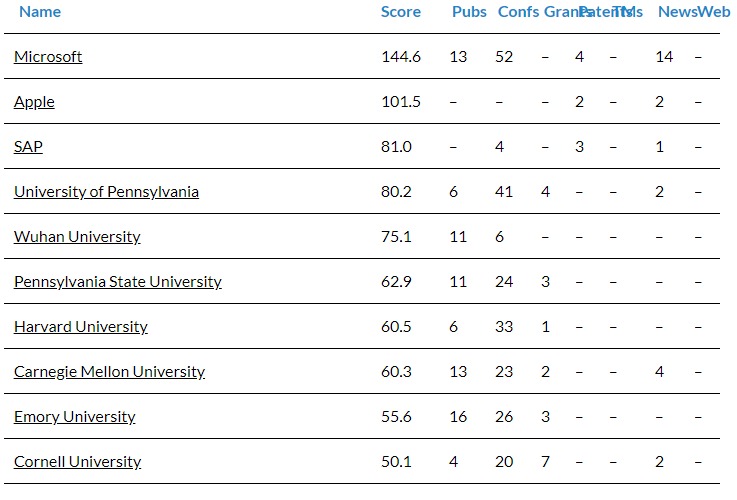
10 führende Unternehmen und Institute weltweit, die Innovationen und Fortschritte im Bereich von Differential Privacy vorantreiben. Quelle: Linknovate.com
Wenn Sie Differential Privacy selber ausprobieren möchten, können Sie dies mit Hilfe von kostenloser Anonymisierungssoftware tun. Eine davon ist PSI, eine Implementierung des Harvard Privacy Tools Projects. Wenn wir Epsilon auf 0.5 setzen, können wir Histogramme der Benutzeranzahl mit 3 Spalten erstellen und den Mittelwert von zwei weiteren bilden. Das Tool schätzte mit 95%iger Fehlerwahrscheinlichkeit den Mittelwert auf 3% und auf die Zählungen auf ±60 (etwa 5% bis 10% für die meisten Histogrammbalken). Das sind nachvollziehbare und nützliche Antworten, aber diese 5 Abfragen haben das Budget erschöpft. Würde man sich strikt an Differential Privacy halten, könnte diese Datenbank (ein kleiner Teil des California Demographic Dataset) nie wieder abgefragt werden. Ein Datensatz mit mehr Zeilen hätte mehr Abfragen mit ähnlichen relativen Fehlerraten zugelassen, aber das Privacy Budget hindert einen Analysten daran, größere Analysen mit einem Datensatz zu erstellen.
Das ARX Data Anonymization Tool verfügt über eine Funktion zur Erzeugung von Mikrodaten, die durch Differential Privacy geschützt sind. Die Ausführung dieser Funktion mit einem Epsilon von 2 auf einem Datensatz mit 16 Spalten und 5369 Zeilen erzeugt einen anonymisierten Datensatz ohne jeglichen Inhalt. Buchstäblich jeder Wert wird durch ein ‘*’ Symbol ersetzt.
Ein interessanter praktischer Anwendungsfall dürfte in naher Zukunft beim statistischen Bundesamt der USA eintreten. Dieses erklärte, dass es für bei der Veröffentlichung der Volkszählungsdaten für 2020 Differential Privacy verwenden wird. Generell könnte das ein Fall sein, der für Differential Privacy wie geschaffen ist, da das Zensusbüro sorgfältig planen kann, wie das Privacy Budget verwendet wird, um den Nutzen zu maximieren. Ein vom Institute for Social Research and Data Innovation (ISRDI) veröffentlichtes Papier argumentiert jedoch, dass die Nutzung von Differential Privacy übertrieben ist und die Aussagekraft der Volkszählungsdaten ernsthaft beeinträchtigen kann. Dies ist ein wichtiger Testfall und es wird sehr interessant zu sehen, wie dieser Fall ausgeht.
Schön in Theorie, mangelnde Praxis
Auf dem Papier besticht Differential Privacy durch den mathematischen Beweis von Privatsphäre. Wenn es nun noch möglich wäre, eine angemessene Nutzbarkeit der Daten bei gleichzeitiger Beibehaltung eines geringen Epsilon-Wertes und überprüfbare Beweise zu gewährleisten, wäre der Durchbruch der Technologie von Forschung in die Praxis sicher. Allerdings steht dieser noch aus – bislang wurde das Konzept in der Praxis nur selten erfolgreich umgesetzt.
Zu guter Letzt können wir auf das Beispiel des zu 100% sicheren Autos zurückkommen. Stellen Sie sich vor, wie ein solches Auto aussehen würde? Wahrscheinlich eher wie ein Panzer als wie ein Auto und für den täglichen Gebrauch eher ungeeignet.
Liste mit weiteren Artikeln zu Differential Privacy
Differential Privacy in den Nachrichten
How One Of Apple’s Key Privacy Safeguards Falls Short
Einsteigerartikel zu Differential Privacy
Differential Privacy: What Is It?
Differential Privacy, An easy case
Differential Privacy Leaders Must Know
Differential Privacy: A Primer for a Non-Technical Audience
Differential privacy in (a bit) more detail
Differential privacy in practice (easy version)
Almost differential privacy
Zur Auswahl eines geeigneten Epsilon
How Much Is Enough? Choosing ε for Differential Privacy
Differential Privacy: An Economic Method for Choosing Epsilon
Data Anonymization Differential Privacy Privacy