In our daily work as a company for a data anonymization solution we are often asked to clarify data anonymization with customers and in personal conversations.
Alarmingly often we hear questions like “What is the difference between anonymization and encryption again?”. But some questions demonstrate serious misunderstandings, which can have equally serious consequences.
To shed some light on this mystery, we present…:
The 7 Myths of Data Anonymization
Myth #1: Anonymization has become important because of the GDPR
In many places, one might wish the GDPR to be more concrete and actionable – but in the distinction between anonymization and pseudonymization it is crystal clear: Only anonymized data is no longer personal and can, therefore, be used extensively and without privacy restrictions.
As a result, the topic is now on everyone’s lips – but of course the same was true in the past. The German Federal Data Protection Act (BDSG) had already made it clear that pseudonymized data are personal data and therefore fell within its scope of application. In the USA, the importance of anonymization for population censuses had already been recognized in the 19th century, and a number of (later computer-aided) methods were developed to protect the privacy of citizens.
The reason why so much importance is attributed to the topic right now is quite different: never before have we generated and recorded data to this extent, much of it personal. It is not the GDPR that is to blame for the sudden interest in anonymization – it is digitisation.
Myth #2: No PII means no personal data
We always prepare ourselves for a long conversation as soon as we hear “We anonymize our data ourselves – we delete the names immediately, we don’t need them for our analyses at all”. Few people know that in fact identifying characteristics (so-called PIIs or Personally Identifiable Information) are often not necessary at all for identification. Years ago, for example, it was shown that 63% of US citizens can be uniquely identified by zip code, date of birth and gender alone.
Even professionals, who supposedly should know better, make this mistake. For example, IBM Watson has recently introduced “anonymization”, which disguises individual columns in three different ways: redaction, substitution (pseudonyms) and masking (similar looking data). None of these methods would be considered anonymizing under European law. If you are interested in the current criteria of anonymization in Europe: Here you can find the paper of the GDPR Working Party 29 that defined the criteria.
Myth #3: Anonymization destroys data and prevents innovation
Yes, anonymization by definition means the removal of certain (namely personal) characteristics from data. This means that details that would be important for certain evaluations can be lost.
However, there are many approaches to anonymization. Modern methods manage to achieve a more effective balance between data quality and data protection. Depending on the application, a different solution may deliver better results and thus enable innovative use of the data. A blog article from our co-founder, Paul Francis, shows how strongly two anonymous heat maps can differ from each other:
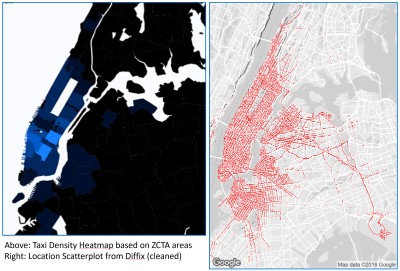
Another point should also be mentioned: in our current environment, we expect our data to be handled correctly – 87% of end customers now report changing service providers if they do not handle their personal data adequately. So anonymization is where the innovation lies.
Myth #4: “Differential Privacy” makes data private
Since Apple’s big announcement about using differential privacy, this approach has been known to many. Unfortunately, it is usually not clear that differential privacy is not an algorithm, let alone a product, but the property of an algorithm. The level of data protection that is guaranteed thus depends on the implementation and many other variables, and (a key point) that can be measured. To say that a database is differentially private does not mean that it is anonymous – but that you can measure how anonymous it is.
Myth #5: Synthetic data is anonymous
Personal information can also be contained in synthetic, i.e. artificially generated, data. A good synthetic data set is based on real connections – how many and how exactly must be carefully considered (as is the case with many other approaches). An example: Karl Müller is the managing director of a 50-man company and pays himself a considerably higher salary. A synthetic data set created on the basis of this company may contain this connection: the managing director is then called Hans Meier, but in order to correctly depict the income structure, he still earns five times as much as his employees. It is therefore easy to draw a conclusion about Mr. Müller.
Modern algorithms for creating synthetic data train machine learning models on the original data and then create new data sets from it, sometimes on demand. This means that personal data that has been integrated into such a model can potentially also be found in the synthetic data. Vitaly Shmatikov, for example, showed in 2017 that ML approaches are susceptible to copying personal data.
Myth #6: AI does not tolerate and does not need anonymous data
Perhaps let’s start with the second point: Of course, the processing of personal data by an artificial “intelligence” is nevertheless processing in the sense of the GDPR, and therefore is regulated by the same. Article 22 even expressly points out that the purely automated processing of personal data is often not permitted (namely if it “significantly affects” the data subject).
The first point is more exciting and controversial: Can modern machine learning take place on the basis of anonymous data? The answer: Yes and no. Many standard algorithms are based on the assumption of having access to raw data. But as an editor of an important journal in this field recently told me: “Just because the algorithms aren’t designed that way doesn’t mean they can’t be designed that way”. The field of “privacy-preserving machine learning” is developing rapidly. At Aircloak, we have been able to train individual models extremely successfully and completely anonymously.
Myth #7: Anonymous data doesn’t exist at all
Just recently I stumbled across this nice tweet:
Hot debate at #AI Policy Congress: is perfectly de-identifiable data possible?
• Industry/gov speakers: “maybe”
• @MIT faculty in audience: “no” pic.twitter.com/bLr8pv9KxD— Ross Dakin (@rossdakin) 15. Januar 2019
A researcher at MIT claims that “perfectly de-identifiable data” is not possible. Is that true? Datasets that have been perfectly anonymized on a large scale are indeed difficult to imagine. Only recently, I had the privilege of moderating a panel in which much of the discussion also revolved around the topic of the measurability of anonymization. As many different opinions as there were, almost all participants agreed on one point: as is the case with IT security, no one hundred percent guarantee can be given, and often there is the need for a risk assessment.
Thus, the whole thing falls back on the definition of anonymity. Depending on the jurisdiction, different standards are applied – often ones that can be met. In Europe, the Article 29 Working Party’s Opinion 05/14 currently still applies here, which says: Data is anonymized when three things are impossible
- the “singling out” of an individual,
- the linking of data points of an individual to create a larger profile (“linkability”)
- and the ability to deduce one attribute from another attribute (“inference”).
It is difficult to comply with these guidelines, but far from impossible. Aircloak Insights, for example, does this automatically before you can say “Privacy is a fundamental right under the European Convention on Human Rights”.
Did you came across other myths related to data anonymization that need to be busted? I’m looking forward to your comments – feel free to send me an email to felix@aircloak.com.
Categorised in: Anonymization, General, Privacy
Data Anonymisation Myths Privacy Enhancing Technologies