Part I
An Abstract Model for Data
Analytics in the Modern World
Before explaining how to choose the best analytics tool stack, we first need to create an abstract model for the stack.
This allows us to discuss the required functionality without being wedded to preconceived ideas about the capabilities and limitations of specific tools such as Postgres.
The inspiration for the following is the well-known TCP-IP model, beloved of network engineers and computer science professors everywhere. That model uses the concept of horizontal abstractions or layers and vertical abstractions or entities.

The Vertical Abstraction
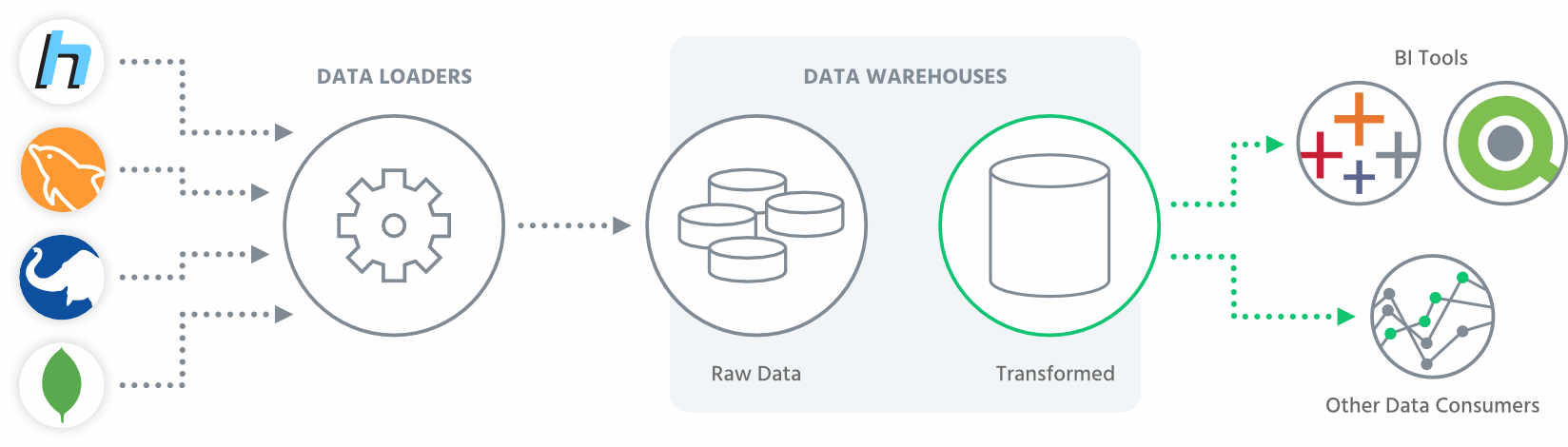
In a 2017 blog post on designing a modular analytics stack, David Wallace at Mode divides the task of data analysis into the following key elements: data collection, data consolidation, data warehousing, data transformation / processing and data analysis / BI.
Each of these modules exists as a discrete entity with data flowing through as shown in the following diagram. Tristan Handy of Fishtown Analytics further refines this model into one consisting of just three main elements.

Data Loader
Modern businesses are generating data constantly. Often this data is an unintentional by-product of the main business process. As a simple example look at geo-tagging of smartphone photos. The primary data in this case is the photo, but the geo-tag provides valuable extra data that can be mined using big data techniques – something that wasn’t fully appreciated by big tech companies originally.
In other cases, the data is a core part of the business (for instance account details for a bank), but there is enormous untapped value in extracting and analysing that data. So, the first element of any data analysis stack needs to collect relevant data from whatever sources are available, consolidate it and pass it on to the next part of the stack.
Data Warehouse
The massive growth in data and in particular the advent of big data has seen the emergence of a new category of data storage, namely the data warehouse. In this abstract model a data warehouse stores all the data collected by the data loader and is able to transform and deliver it in the required form to the data consumer.
Here we are using data warehouse to cover any form of entity used for storing data for later analysis. In some cases, this may be an actual data warehouse (e.g. a massive data store in a cloud-connected data centre), but in other cases it may simple be a storage server in your own premises.
Data Consumers
The final piece of this model is the data consumer. There are many types of data consumers, but essentially most of them seek to take the data passed to them and extract useful business intelligence or insights from it. Some data consumers are automated dashboards, others might be a skilled data analyst. Or they may be a senior executive trying to get some summary figures to show how the business is growing and performing.
A key thing to note is that not all data consumers are internal to your organisation. They may be a contractor or a collaborator, or they may be a 3rd party organisation buying your data.
The Horizontal Abstraction
The vertical abstraction just described identifies the discrete elements or entities within the system, but it doesn’t identify the required functionality. For that we need to look at a horizontal abstraction where we divide the problem into layers. Each layer represents a functional abstraction.
As you will see, the entities in the previous section are composed of different sets of these underlying functions.

Data Ingestion
Locating raw data and ingesting it is the fundamental function of an analytics stack. Often this process will require ingesting large streams of data which may even be generated in real-time (for instance data coming from fitness trackers). One of the most important aspects here is data provenance.
You have to know where the data came from and if there were any restrictions attached to using the data. If there were existing restrictions, then these need to be recorded as part of the metadata for this data.
Data Extraction, Transformation and Loading (ETL)
ETL is the process of taking the raw data found during the ingestion stage, extracting the meaningful/useful data from it, transforming it to a suitable form for your chosen storage medium (e.g. key-value store, blob store, relational database, etc.) and finally loading the data into the storage. In the past, one of the key jobs of ETL was to reduce the data down to a manageable size for storage. This often meant being quite aggressive with the extraction stage.
Nowadays, the significantly reduced cost of storage often means it’s better to try and store as much of the original data as possible. In the future, this data may well prove to be valuable to you, and if you haven’t stored it you can never recover it.
Data Cleaning
The data cleaning function covers several aspects including finding and removing corrupt data, finding and removing duplicates and removing irrelevant data. Where data has been generated as part of a large stream this process may be quite extensive, and depending on the source of the data, it can be hard. As an example, if the data consists of medical notes, you may need to use some form of OCR (optical character recognition) along with Natural Language Processing (NLP) to extract the underlying meaning in the data.
As data science develops as a discipline, new cleaning functions are emerging, such as identifying duplicate entities that exist across multiple datasets.
Security and Privacy
Technically, data security and data privacy are separate concepts, but within this abstraction they happen in the same layer. Data security refers to the process of ensuring only authorised people are able to access and interact with the data while data privacy refers to the process of ensuring that any data that is revealed outside your security perimeter doesn’t contain personal identifiers, except where such data sharing is allowed.
Data Analysis
Performing the actual analysis of the data to extract useful insights and information is the main point of data analytics. This function covers a whole range of tasks from query generation to constructing complex algorithms and using machine learning to process data.
Data Presentation
The highest layer in this abstraction is data presentation. Here the results of the analysis are presented in a usable form through visualisations or other techniques. This is where the data can finally be used for business intelligence, planning or review.
Some presentation tasks may relate to metadata, for instance visualising the size of a database or illustrating the nature of the data being stored.
Combining the Abstractions
To create a full model of the analytics stack we need to combine the horizontal and vertical abstractions. The following image illustrates how these elements work together.

In the figure above, functions can either form a key part of an entity, or they can be a subsidiary function. What you will notice is that Security and Privacy is the only function that exists across all the entities. This is because at every stage you have to ensure you are keeping your data secure and are preventing personal data from being leaked.
Applying the Model
The abstract model above is deliberately vague about how it relates to real tools. In this section we will see a couple of examples that show how the model can be used to describe the functionality of standard tools.
Databases
Databases are one of the core components of the data warehouse entity. Once, companies may have relied on monolithic relational databases such as Oracle for handling all their data.
Nowadays there are a plethora of options, and often several different databases may be used in combination to achieve the required storage. Functionally, databases exist mainly at the ETL layer, but they also may include ingestion, security & privacy and some presentation functions (relating to the metadata about the actual database).
Visualisation Tools
Visualisation is one of the main tools in any data analyst’s toolbox. There are many visualisation packages and approaches out there, from constructing graphs using Excel or R to displaying live dashboards using applications like Tableau. Clearly visualisation is a Data Consumer within the definition above. Equally clearly the main functionality is at the Presentation Layer.
However, it also includes significant elements of:
- Data Privacy – since it is essential to make sure only appropriate data is being displayed,
- Analysis – often the analysis is done on the fly within the tool
- and even Cleaning, since sometimes it’s only after visualisation that you can identify superfluous or duplicate data.
Excursus: Other Data
Abstractions and Standards
There are numerous other abstractions and data standards that have been developed over the years. Often these have been created for specific industries or use cases and are narrowly defined. In the modern world, larger amounts of personal data are being gathered than ever before. While all the data can be generically described as “personal”, the actual uses for the data vary widely. Equally, some of the data is more sensitive than other data. As an example, detailed medical records are often far more sensitive than the history of what online purchases you made.
All these different use cases and types of personal data need different models and architectures for storage, use and analysis. This is especially the case for the most sensitive data like health records and financial records. Below we give some examples of alternative abstractions.

More and more health data gets collected by devices like smartwatches and makes data transparency, privacy and security an much more important topic than it ever was before.
Information Models Are Used
to Describe Data in an Abstract Fashion
The model typically explains what the data is and the semantics of how to interpret it, how the different elements relate to each other and any constraints and rules that should be applied. The aim of the model is to provide a rigorous framework within which to describe how data is used in a given domain. Information models are used to map real-world problems into an abstract space in order to simplify the process of creating software. A good example of this might be a process model for a production line.
Information models are often highly complex and abstract.
A number of specific languages have been devised to try to explain or illustrate them, including IDEF1X and EXPRESS. One of the most famous of these is the Unified Modelling Language (UML) which provides a set of diagram types to describe how data and artefacts flow through a software program.
These diagrams include Structure Diagrams such as Class Diagrams which describe the data and Behaviour Diagrams such as Use Case Diagrams or State Machine Diagrams that describe what the system should achieve with the data and how different elements within the system interact with each other.
Models for Clinical Data
CDISC, the Clinical Data Interchange Standards Consortium, is a global non-profit organisation dedicated to producing data standards relating to clinical research. They have a number of data standards such as ADaM (the Analysis Data Model), which defines the dataset and metadata used for analysis of clinical trials.
PhUSE (the Pharmaceutical Users Software Exchange) is a non-profit organisation set up by data scientists within the clinical and pharmaceutical industries. Among other working groups they have a group looking at data standards for use in this field. While PhUSE is not an official standards body, their work directly influences bodies such as CDISC and the US Food and Drug Administration (FDA) who create these standards.
Models for Financial Data
The EU second Payments Services Directive (PSD2) has driven a demand for new models of financial data. One of the key aims of PSD2 has been to open up competition in the banking market. In order to do this, there is a need for rigorous models for financial data. These models are designed to allow data to be exchanged securely and easily between financial institutions. It has also become one of the drivers for the booming fintech industry across Europe.
One of the most successful data models has come out of the Open Banking Initiative. This has defined standards and APIs for open banking that can then be used to build commercial fintech products. In the context of this paper, the most relevant standards are the Account Information API, which provides a way to safely access and share customer account data.
Data Origination and Data Exchange
It’s useful to briefly digress here and consider two things that are closely related to data analysis. These are data origination and data exchange. Neither data origination, nor data exchange are directly part of the analytics stack, but they are key elements that need to be considered in any model of the stack.
In almost all systems, data isn’t static.
New data is constantly being generated (data origination). Let’s take the simple example of a patient’s health record. Every time a patient visits their doctor, their record will be updated with notes about the consultation, the results of any tests and observations and any medicines that have been prescribed. Some of this data forms part of their permanent record, but other data expires. To make it more complicated, some data such as prescribed medicine is only valid in the short term, but the fact they have had that medicine should form part of the long-term record.
Now, when the patient attends the pharmacy to collect their medicine, the pharmacist may need to access their patient record to check the details of the prescription. Later on, the patient’s health insurer will also need to check the details of the transaction. These are examples of data exchange.
Another increasingly common example of data exchange is fintech apps that allow you to aggregate all your bank account data into one place. Like data analysis, data security is essential during data exchange, and the receiving party will need to be responsible for the privacy of the data.
Building a Privacy-preserving analytics stack – better understand how to comply with the requirements imposed by GDPR while still leveraging data analysis.

Part II:
Ensuring Data Security and Privacy
In this section we will explore the Data Security and Privacy function in detail. We will explain in detail what we mean by each term and explore some of the techniques used.