LINC, the innovation lab of the French data protection authority CNIL, has been exploring the uses of anonymized data in projects like CabAnon. This project explores uses of the NYC taxi database for applications like planning new transportation services. The results, published the article “Can anonymized data still be useful”, demonstrate that in some cases anonymized data can be useful.
Inspired by that article, I thought I’d have a look at what can be done with the NYC taxi data using Diffix. Diffix is an anonymization scheme developed jointly between the Max Planck Institute for Software Systems (MPI-SWS) and Aircloak, and commercially marketed by Aircloak. Diffix is a dynamic anonymization mechanism, meaning that it anonymizes each query, versus more traditional static approaches that anonymize the entire database all at once.
As with LINC, we use the term anonymization in the strong sense. Diffix provides strong anonymization in that it is extremely unlikely that an analyst can isolate or identify individuals in the data even with substantial external knowledge.
What LINC Did
The taxi database contains one entry per ride. Each entry gives the start and end times and locations for the ride. The use cases that LINC focused on use this data. The taxi database, however, contains a lot of other information: the taxi identifier, the driver identifier, the fare and tip amounts, the taxi vendor, and the number of passengers.
The use case for LINC was to determine if additional new transportation services are needed. For this use case LINC decided that data at the location granularity of ZIP Code Tabulation Areas (ZCTA, roughly corresponds to US zip code areas) and time granularity of 30 minutes would suffice. To ensure anonymization, data for ZCTA’s with fewer than 10 taxis per time window was removed. This amounts to K-anonymization with K=10. This anonymization can be visualized as a heatmap, as shown in the left hand image below (taken from the LINC article). In comparison the right image shows a scatterplot of pickup locations as anonymized using Diffix.
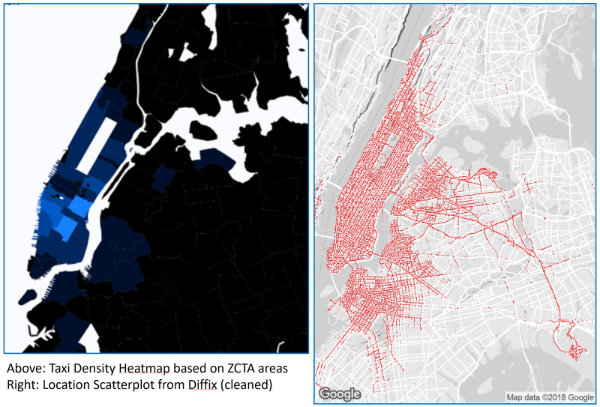
LINC takes a classic approach to anonymization — customize the anonymization to satisfy a specific use case. In this case, LINC did not need data about payments, taxi drivers, trip lengths, and so on, so that data could be thrown out. Had that data been needed, then LINC might have taken a different approach to anonymization, and may not even have been able to anonymize the data adequately.
What Diffix Does
Diffix is a system that is deployed in front of a database containing raw (non-anonymized) data. Diffix intercepts SQL queries made to the database, and anonymizes the answers by placing limitations on the SQL and by adding noise. The database may be a relational database or a NoSQL datastore. This query-by-query approach has two advantages. First, Diffix applies only as much noise as is needed for each query, thus minimizing data distortion. Second, Diffix eliminates the need to manually design an anonymization scheme to fit the use case. In essence, Diffix regards each query as a separate use case, and anonymizes appropriately.
To do its job, Diffix has to be told what to protect. For this analysis, we configured Diffix to protect the privacy of the taxi driver.
By way of example, consider the scatterplot of taxi pickup locations shown in the figure above. The dots in this image do not represent individual taxi pickups, but rather represent pickups that took place within boxes of approximately 10 meters X 10 meters (granularity of four decimal places in the GPS coordinates). Diffix automatically removed any boxes that did not have enough distinct taxi drivers, the threshold being on average 4 taxi drivers. If we had asked for full granularity, Diffix would have removed more than 90% of the locations.
Because Diffix anonymizes query-by-query, the full set of database attributes are available to us as analysts. There are therefore a wide variety of use cases we could examine simply by writing the appropriate SQL query. In what follows, we select three use case that should give the reader a good sense of what is possible with Diffix.
Anybody traveling to LaGuardia to catch a flight needs to know how long it may take to get to the airport. Since taxis frequently travel to the airports, we can answer this question with taxi data.
The following visualizations are scatterplot heatmaps showing the average time to LaGuardia from any location for which enough taxi data exists. We look at three different time periods: the hour from 13:00 to 14:00 on weekends, the hour from 8:00 to 9:00 on weekdays, and the hour from 17:00 to 18:00 on weekdays. These three time periods are chosen to contrast non-rush hour with rush hour, and to contrast the morning rush from the evening rush. In each case, the left-hand figure shows the raw data, and the right-hand figure is for Diffix (labeled Cloak).
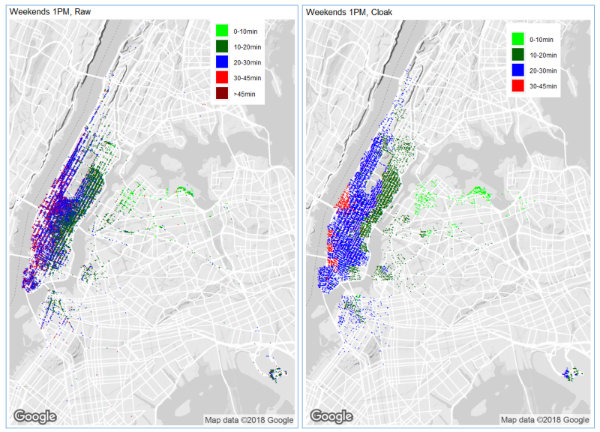
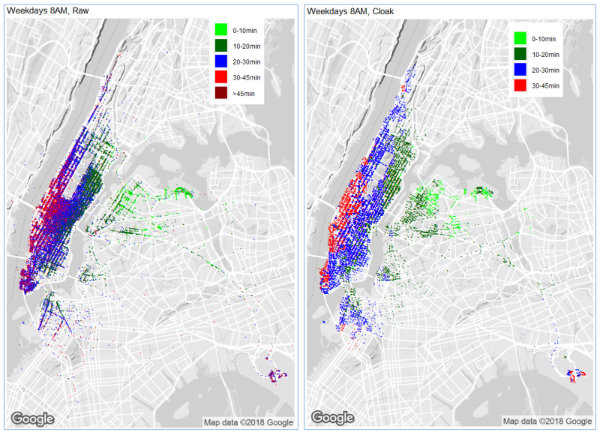
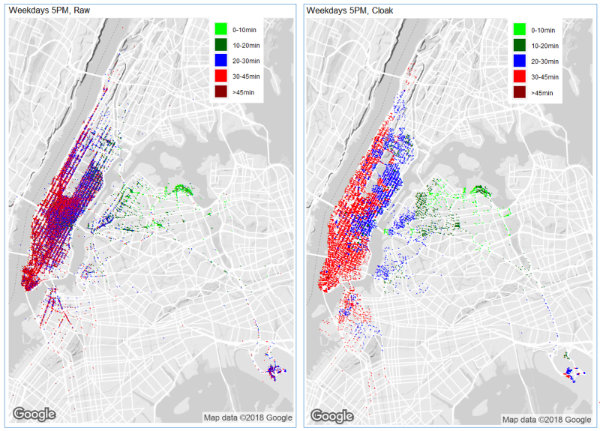
Note in particular that the distortion introduced by Diffix’ anonymization does not change the basic conclusions that may be drawn from the visualizations — the travel time from any area for which data exists is roughly the same for the raw data and the anonymized data.
One item that we found interesting is that there are a lot of rides that start and end at LaGuardia, and that many of these rides fall in the 10–20 minute range. One possible explanations for the short time durations is that travelers in a hurry take a taxi between terminals rather than the shuttle bus. Regarding the longer time durations, perhaps travelers on layover visit some location away from the airport.
Government officials or social scientists might be interested in understanding the work profiles for drivers. While the taxi data identifies the driver, it unfortunately doesn’t carry any other information about drivers (for instance age, duration of employment, number of sick days taken, whether they have health insurance, etc.). Nevertheless, we can learn some interesting things about driver behaviour.
The first question we ask is, how many days per year does each driver work? The following plots that information as a histogram with one data point per day. Note the log scale for number of drivers. A day is counted so long as the driver had at least one pickup during the day. Note that this will over-count drivers who work nights, since one night of work will be counted as two days if the driver starts before midnight.
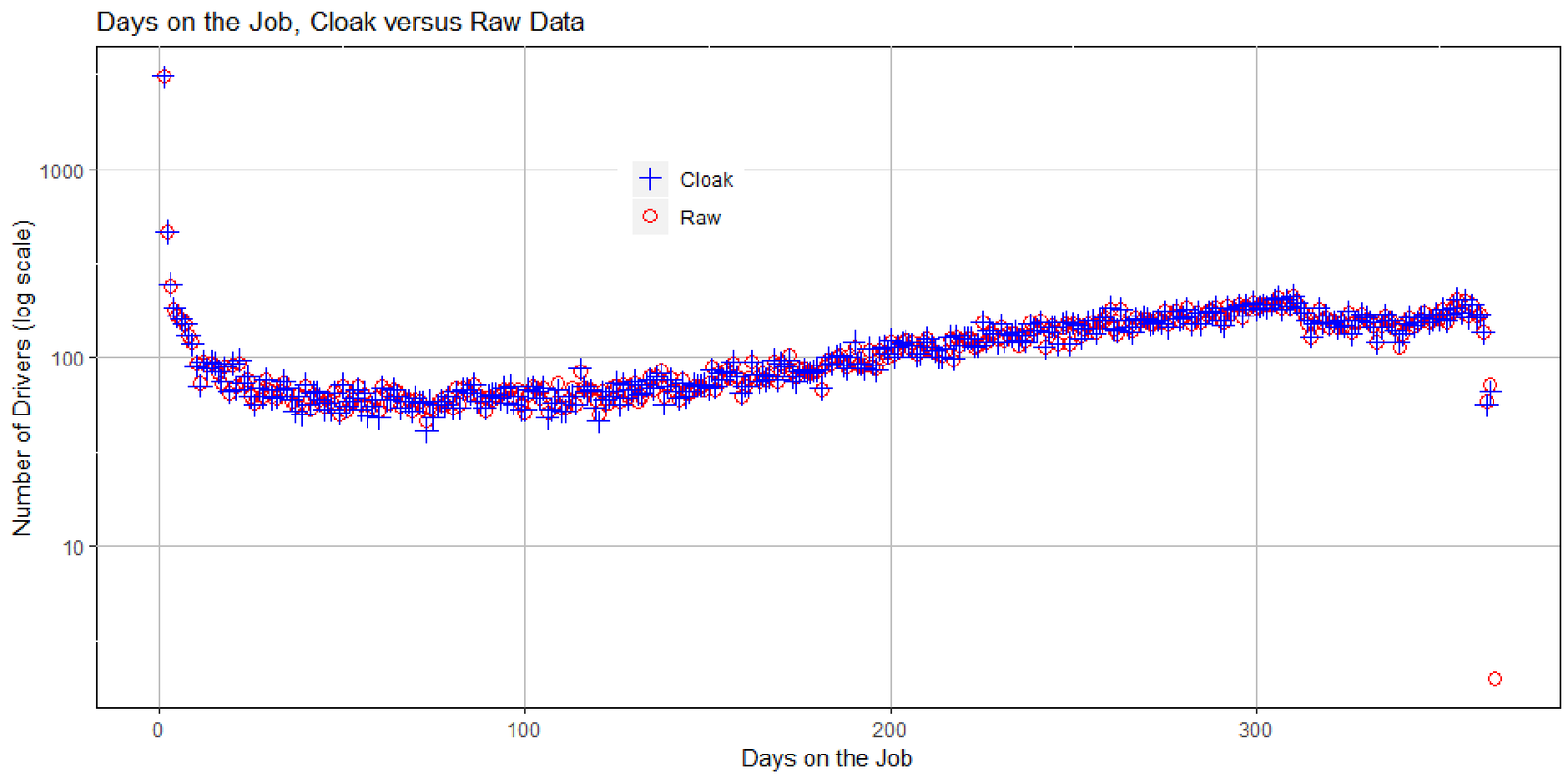
The graphs shows both anonymized (labeled Cloak) and raw data. Note that the anonymized counts are very accurate. Note also that the last raw data point does not have an anonymized counterpart. Diffix suppressed that data point because it refers to too few users, and so could in principle violate anonymity. (As a note of interest, that data point is for two drivers who worked every day of the year!)
This graph tells us a number of interesting things. There are a lot of drivers who worked only one or a few days. Over 3000 drivers worked only one day. I would guess that this represents a trial period where either the employee or the employer decided that taxi driver is the wrong job for that person.
The large majority of taxi drivers work on a part-time basis — everything from just a month or two upwards. There could be many reasons for this. Perhaps some drivers work seasonally, drive taxis as a second job, or drive taxis during periods of unemployment.
The next graph shows how many hours per day, on average, each driver works. In particular, we want to see if drivers that work very many days work different hours per day than drivers that don’t work very many days. So that the data clearly distinguishes these two groups, we chose one group as having more than 300 days per year (labeled CloakFull), and the other group as having between 100 and 150 days per year (labeled CloakPart). Here we only show the anonymized data—the raw data is virtually the same (with the exception of a few very hard workers that were suppressed by Diffix).
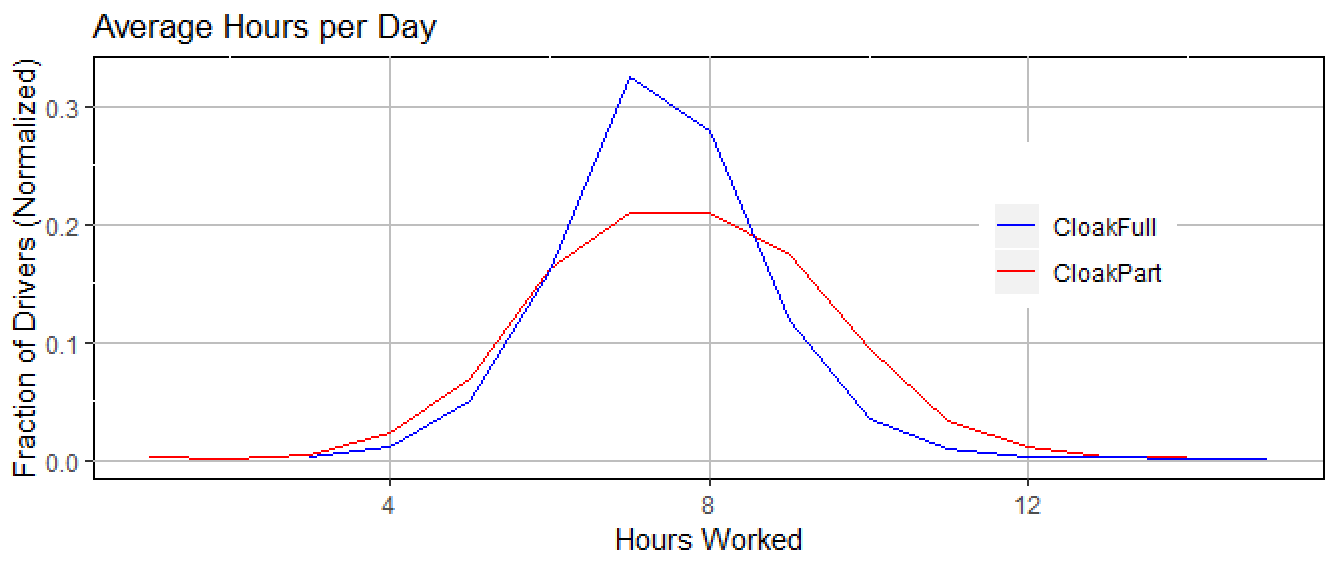
This shows that taxi drivers tend to have normal work times (roughly 6 to 8 hours) whether or not they work few days or many days and that “part-time drivers” tend to have slightly longer work times.
The taxi data is well suited to studying congestion in the city. This is something that city planners as well as transportation companies are interested in.
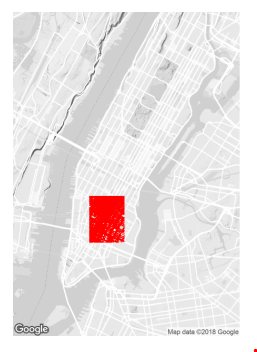
As an example of this kind of study, we queried for the speed in miles-per-hour of all rides where both the pickup and dropoff were within the region denoted by the box above. This represents a large portion of the financial district in Manhattan. (This image is itself created by querying Diffix for pickup and dropoff locations in 10-meter boxes.)
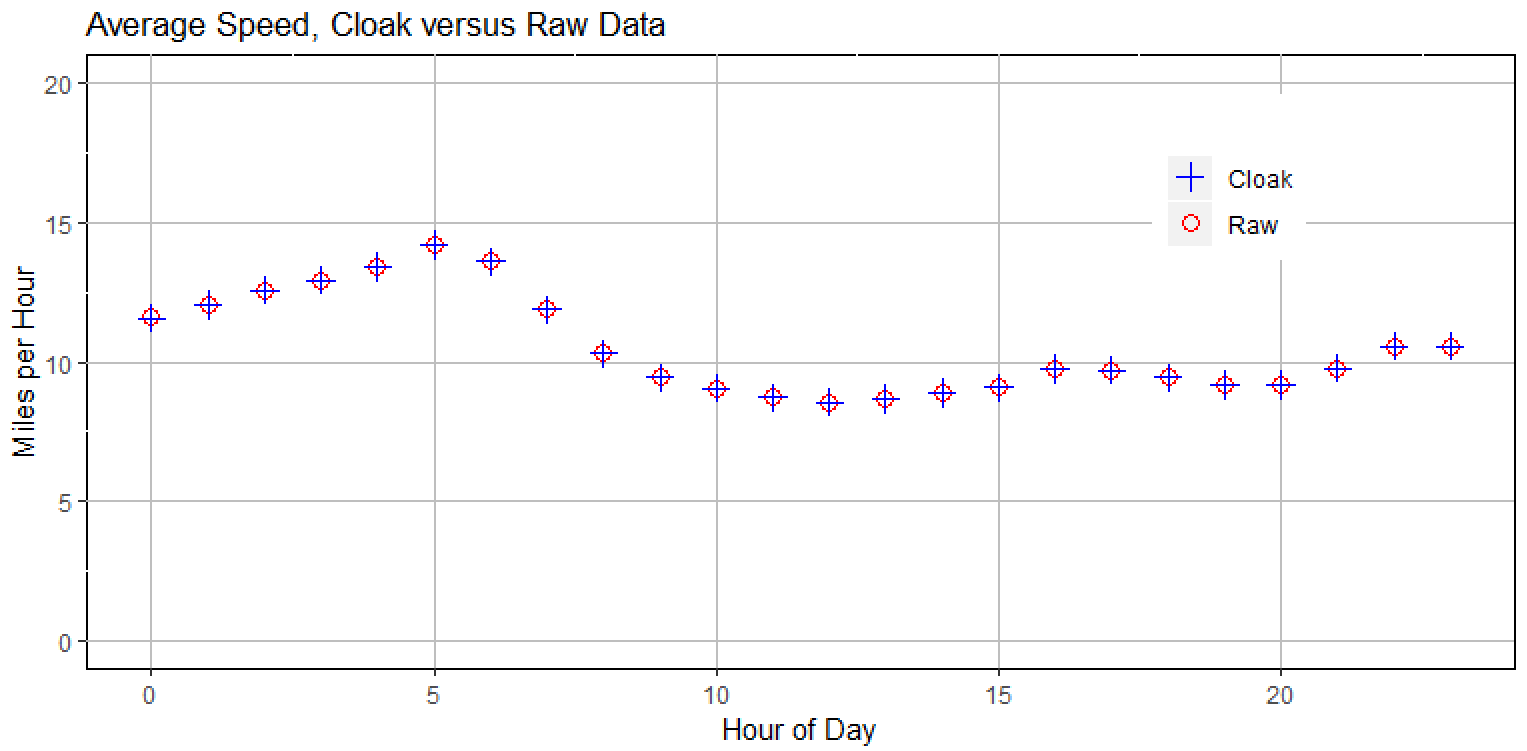
The results are shown in the following graph, where speed is computed as distance/time. Starting at midnight, we can see that speed increases through the night until 5AM, suggesting that activity in the city only slowly tapers off through the night (also lending credence to the label as the city that never sleeps).
The main conclusion that I draw from this article, and I hope the reader agrees with me, is that we can have rich and accurate analytics while maintaining strong anonymity. In fact, it is a common opinion among privacy professionals that strong anonymity prevents useful analytics, and indeed prior to Diffix that opinion was largely justified. We hope that this article serves to change that opinion.
Categorised in: Aircloak Insights, Anonymization, Privacy
CabAnon CNIL Data LINC NYX Taxi Database Usefulness